在实际中遇到这样一个问题,公司软件发布上线自动化。
说简单点,就是需要去登录一个上线的内部网站,然后爬下所有的上线数据。
然后根据爬下来的数据整理好,可以一起上线的,就并发多线程,其实就是去传参数点击一个链接等返回。
不能并发的就单线程点链接。
那这个事情必须更有效率,单线程的没问题,用 python 的 request 就可以实现了。
我们仔细研究一下协程,先讲一下历史:
使用Python的人往往纠结在多线程、多进程,哪个效率更高?到底用哪个好呢?
其实 Python 的多进程和多线程,相对于别家的协程和异步处理机制,都不行,线程之间切换耗费 CPU 和寄存器,OS 的调度不可控,多进程之间通讯也不便。性能根本不行。
后来呢 Python 改进了语法,出现了 yiled from 充当协程调度,有人就根据这个特性开发了第三方的协程框架,Tornado,Gevent等。
官方也不能坐视不理啊,任凭别人出风头,于是 Python 之父深入简出3年,苦心钻研自家的协程,async/await 和 asyncio 库,并放到 Python3.5 后成为官方原生的协程。
对于 http请求、读写文件、读写数据库这种高延时的 IO 操作,协程是个大杀器,优点非常多;它可以在预料到一个阻塞将发生时,挂起当前协程,跑去执行其它协程,同时把事件注册到循环中,实现了多协程并发,其实这玩意是跟 Nodejs 的回调学的。
看下图,详细解释下,左边我们有100个网页请求,并发100个协程请求(其实也是1个1个发),当需要等待长时间回应回应时,挂起当前协程,并注册一个回调函数到事件循环(Event Loop)中,执行下一个协程,当有协程事件完成再通过回调函数唤醒挂起的协程,然后返回结果。
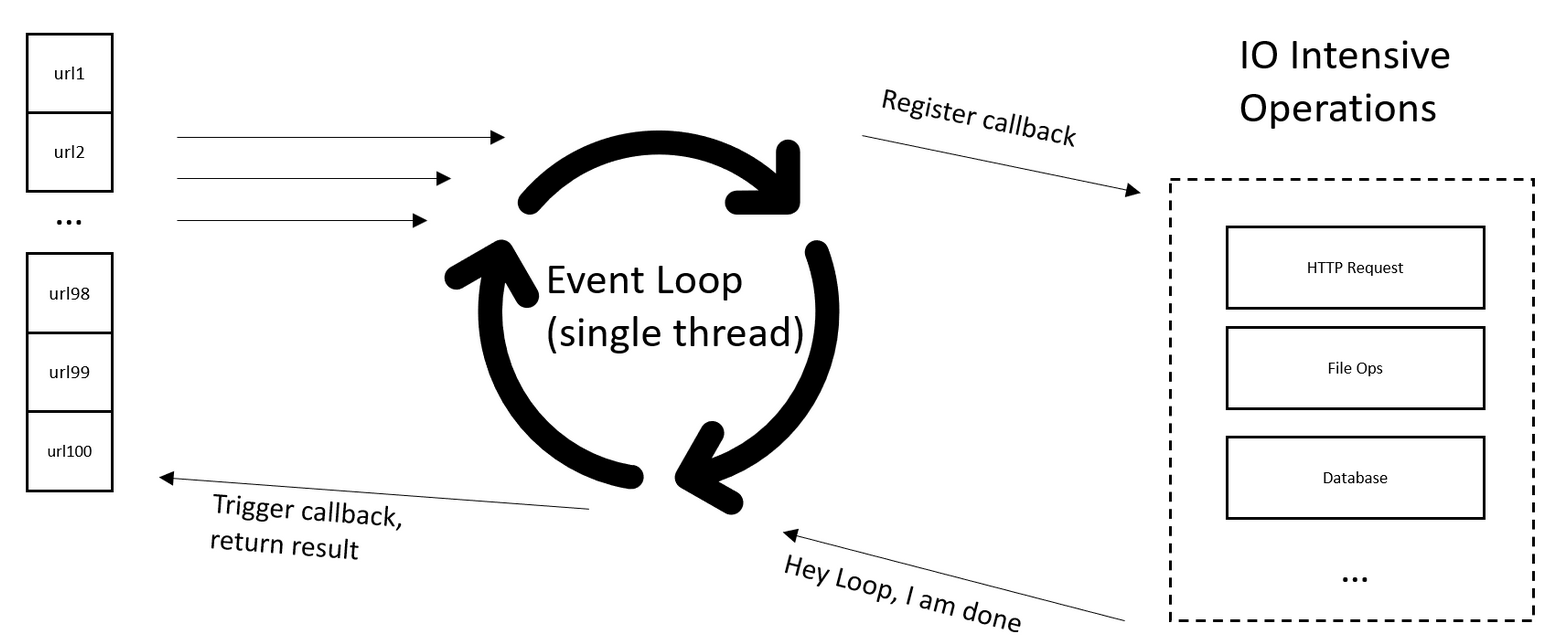
这个跟 nodejs 的回调函数基本一样,我们必须注意主进程和协程的关系,如果我在一个主进程中,触发协程函数,有100个协程,那么必须等待100个协程都结束后,才能回到正常的那个主进程中。当然,主进程也可能也是一个协程。
那么协程的基本用法
-
async f(n) 声明一个函数是协程的
-
await f(n) 挂起当前协程,把控制权交回 event loop,并且执行f(n)和注册之后的f(n)回调。
举个例子:如果在 g() 这个函数中执行了 await f(),那么g()函数会被挂起,并等待 f() 函数有结果结束,然后返回 g() 继续执行。
1async def get(url):
2 async with aiohttp.ClientSession() as session:
3 async with session.get(url) as response:
4 return await response.text()
最后一行 await 是挂起命令,挂起当前函数 get() ,并执行 response.text() 和注册回调,等待 response.text() 执行完成后重新激活当前函數get()继续执行,返回。
所以 await 只叫做挂起是不太对的,感觉应该叫做 挂起并注册回调 比较合适。
看以下程序,在 Python 3.7 之前,协程是这么用的:
1import time
2import asyncio
3
4now = lambda : time.time()
5
6async def do_some_work(x):
7 print('Waiting: ', x)
8
9start = now()
10coroutine = do_some_work(2)
11loop = asyncio.get_event_loop()
12loop.run_until_complete(coroutine)
13print('TIME: ', now() - start)
我们指定了一个协程 coroutine ,然后定义了一个事件循环 loop,loop 是需要 run_until_complete 所有的协程,然后交出控制权,返回正常的主进程。
跟上图完全匹配。
在 Python 3.7 之后,简化了用法,一句 asyncio.run 就可以了:
1asyncio.run(do_some_work(2))
上面程序就变了,省了好多,但是副作用是第一次看到的人会不明白它是怎么进化过来的:
1import time
2import asyncio
3
4now = lambda : time.time()
5
6async def do_some_work(x):
7 print('Waiting: ', x)
8
9start = now()
10asyncio.run(do_some_work(2))
11print('TIME: ', now() - start)
如果我们要访问一个网站的100个网页,单线程的做法是:请求一次,回来一次,然后进行下一个
1for url in urls:
2 response=get(url)
3 results=parse(response)
这样效率很低,协程呢,做法就不同了,一次发起100个请求(准确的说也是一个一个发),不同的是协程不会死等返回,而是发一个请求,挂起,再发一个再挂起,发起100个,就挂起100个,然后注册并等待100个返回,效率提升了100倍。可以理解为同时做了100件事,做到由自己调度而不是交给CPU,程序的并发由自己来控制,而不是交由 OS 去调度,效率极大的提高了。
进化到协程,我们把费 IO 的 get 函数抽出来放到协程里:
1async def get(url:str):
2 my_conn = aiohttp.TCPConnector(limit=10)
3 async with aiohttp.ClientSession(connector=my_conn) as session:
4 async with session.get(url) as resp:
5 return await resp.text()
6
7
8for url in urls:
9 response=asyncio.run(get(url))
10 results=parse(response)
11
具体到我们的项目,我们首先要登录一个网页拿到 cookie,这个过程其实就一个协程,没人会登录个几百次吧。然后把放了 cookie 的 session 取出来,供后面的协程再复用就可以了,示例代码如下:
1import aiohttp
2import asyncio
3
4async def login():
5 my_conn = aiohttp.TCPConnector(limit=10)
6 async with aiohttp.ClientSession(connector=my_conn) as session:
7 data = {'loginname':'wangbadan','password':'Fuckyouall'}
8 async with session.post('http://192.168.1.3/user/login',data=data) as resp:
9 print(resp.url)
10 print(resp.status)
11 print(await resp.text())
12 return session
13
14session = asyncio.run(login())
15print(f"{session}")
再给一个完全版的主函数是进程,下载是协程的例子,注意里面的 aiohttp.TCPConnector(limit=10),限制一下并发是10个,否则会被服务器 Ban 掉:
1import asyncio
2import time
3import aiohttp
4from aiohttp.client import ClientSession
5
6async def download_link(url:str,session:ClientSession):
7 async with session.get(url) as response:
8 result = await response.text()
9 print(f'Read {len(result)} from {url}')
10
11async def download_all(urls:list):
12 my_conn = aiohttp.TCPConnector(limit=10)
13 async with aiohttp.ClientSession(connector=my_conn) as session:
14 tasks = []
15 for url in urls:
16 task = asyncio.ensure_future(download_link(url=url,session=session))
17 tasks.append(task)
18 await asyncio.gather(*tasks,return_exceptions=True) # the await must be nest inside of the session
19
20url_list = ["https://www.google.com","https://www.bing.com"]*50
21print(url_list)
22start = time.time()
23asyncio.run(download_all(url_list))
24end = time.time()
25print(f'download {len(url_list)} links in {end - start} seconds')
协程里的 session 也有很多种用法,参考下面的链接就好:
https://blog.csdn.net/weixin_39643613/article/details/109171090
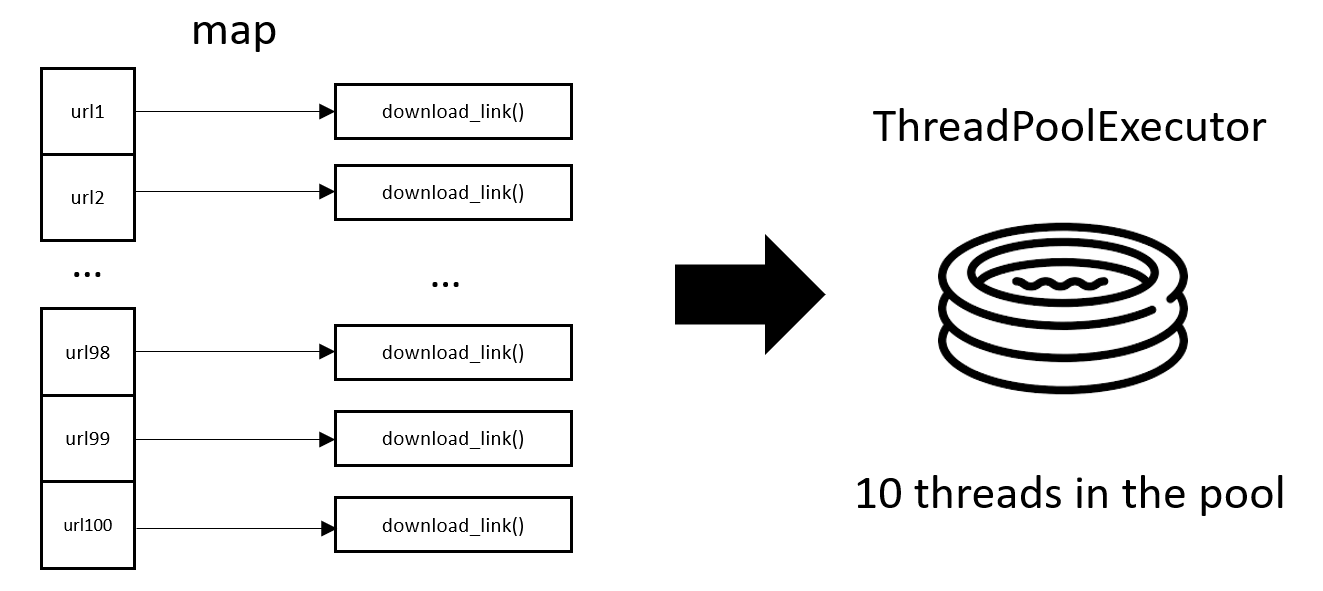
我们也给出简单易用的线程池版,说不定以后会用上:
1import requests
2from requests.sessions import Session
3import time
4from concurrent.futures import ThreadPoolExecutor
5from threading import Thread,local
6
7url_list = ["https://www.google.com/","https://www.bing.com"]*50
8thread_local = local()
9
10def get_session() -> Session:
11 if not hasattr(thread_local,'session'):
12 thread_local.session = requests.Session()
13 return thread_local.session
14
15def download_link(url:str):
16 session = get_session()
17 with session.get(url) as response:
18 print(f'Read {len(response.content)} from {url}')
19
20def download_all(urls:list) -> None:
21 with ThreadPoolExecutor(max_workers=10) as executor:
22 executor.map(download_link,url_list)
23
24start = time.time()
25download_all(url_list)
26end = time.time()
27print(f'download {len(url_list)} links in {end - start} seconds')

