kubernetes 的动态伸缩 HPA 是非常有用的特性。
我们的服务器托管在阿里云的 ACK 上,k8s 根据 cpu 或者 内存的使用情况,会自动伸缩关键 pod 的数量,以应对大流量的情形。而且更妙的是,动态扩展的 pod 并不是使用自己的固定服务器,而是使用阿里动态的 ECI 虚拟节点服务器,这样就真的是即开即用,用完即毁。有多大流量付多少钱,物尽其用。
我们先明确一下概念:
k8s 的资源指标获取是通过 api 接口来获得的,有两种 api,一种是核心指标,一种是自定义指标。
-
核心指标:Core metrics,由metrics-server提供API,即 metrics.k8s.io,仅提供Node和Pod的CPU和内存使用情况。api 是
metrics.k8s.io -
自定义指标:Custom Metrics,由Prometheus Adapter提供API,即 custom.metrics.k8s.io,由此可支持任意Prometheus采集到的自定义指标。api 是
custom.metrics.k8s.io和external.metrics.k8s.io
一、核心指标metrics-server
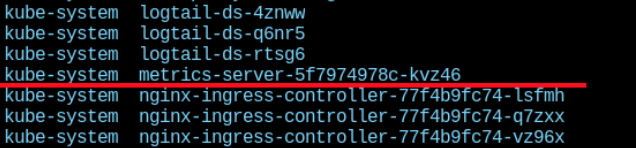
阿里的 ACK 缺省是装了 metrics-server 的,看一下,系统里有一个metrics-server
1kubectl get pods -n kube-system
再看看 api 的核心指标能拿到什么,先看 Node 的指标:
1kubectl get --raw "/apis/metrics.k8s.io" | jq .
2kubectl get --raw "/apis/metrics.k8s.io/v1beta1" | jq .
3kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
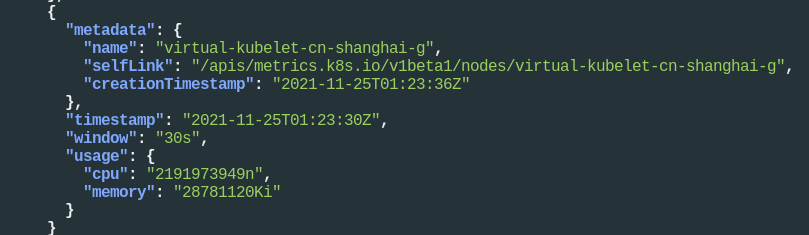
可以看到阿里 eci 虚拟节点的 cpu 和 memory 资源。
再看看 Pod 的指标:
1kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
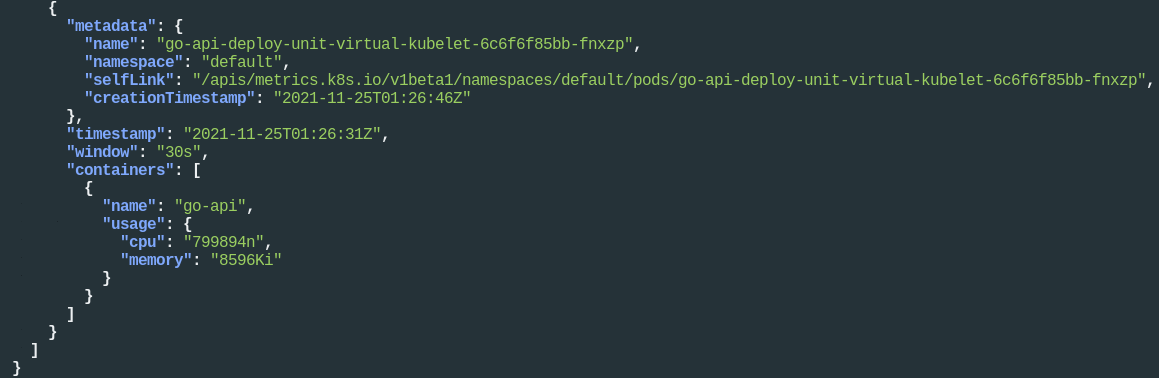
可以清楚得看到调度到虚拟节点上的 Pod 的 cpu 和 memory 资源使用情况。大家看到只有 cpu 和 memory,这就够了。
给个全部使用自己 Work Node 实体节点伸缩的例子:
php-hpa.yaml (这里定义了平均cpu使用到达80%或者内存平均使用到200M就伸缩):
php-hpa 规范了 php-deploy 如何伸缩,最小2,最大10:
1apiVersion: autoscaling/v2beta1
2kind: HorizontalPodAutoscaler
3metadata:
4 name: php-hpa
5 namespace: default
6spec:
7 scaleTargetRef:
8 apiVersion: extensions/v1beta1
9 kind: Deployment
10 name: php-deploy
11 minReplicas: 2
12 maxReplicas: 10
13 metrics:
14 - type: Resource
15 resource:
16 name: cpu
17 targetAverageUtilization: 80
18 - type: Resource
19 resource:
20 name: memory
21 targetAverageValue: 200Mi
再给个阿里 ACK 使用 ECI 虚拟节点伸缩的例子:
我们首先定义一个正常的 deployment ,php-deploy,这个就正常定义跟别的没区别。
然后再定义扩展到 eci 节点的 ElasticWorload,elastic-php,这个用来控制 php-deploy 拓展到 eci 虚拟节点去
下面是固定6个,动态24个,合计30个
1apiVersion: autoscaling.alibabacloud.com/v1beta1
2kind: ElasticWorkload
3metadata:
4 name: elastic-php
5spec:
6 sourceTarget:
7 name: php-deploy
8 kind: Deployment
9 apiVersion: apps/v1
10 min: 0
11 max: 6
12 elasticUnit:
13 - name: virtual-kubelet
14 labels:
15 virtual-kubelet: "true"
16 alibabacloud.com/eci: "true"
17 annotations:
18 virtual-kubelet: "true"
19 nodeSelector:
20 type: "virtual-kubelet"
21 tolerations:
22 - key: "virtual-kubelet.io/provider"
23 operator: "Exists"
24 min: 0
25 max: 24
26 replicas: 30
然后定义 HPA php-hpa 来控制 elastic-php 的自动伸缩
1apiVersion: autoscaling/v2beta2
2kind: HorizontalPodAutoscaler
3metadata:
4 name: php-hpa
5 namespace: default
6spec:
7 scaleTargetRef:
8 apiVersion: autoscaling.alibabacloud.com/v1beta1
9 kind: ElasticWorkload
10 name: elastic-php
11 minReplicas: 6
12 maxReplicas: 30
13 metrics:
14 - type: Resource
15 resource:
16 name: cpu
17 target:
18 type: Utilization
19 averageUtilization: 90
20 behavior:
21 scaleUp:
22 policies:
23 #- type: percent
24 # value: 500%
25 - type: Pods
26 value: 5
27 periodSeconds: 180
28 scaleDown:
29 policies:
30 - type: Pods
31 value: 1
32 periodSeconds: 600
上面的 ElasticWorkload 需要仔细解释一下,php-deploy 定义的 pod 副本固定是6个,这6个都是在我们自己节点上不用再付费,然后 ECI 的 pod 副本数是0个到24个,那么总体pod数量就是 6+24 = 30 个,其中 24个是可以在虚拟节点上伸缩的。而 php-hpa 定义了伸缩范围是 6-30,那就意味着平时流量小的时候用的都是自己服务器上那6个固定 pod,如果流量大了,就会扩大到 eci 虚拟节点上,虚拟节点最大量是24个,如果流量降下来了,就会缩回去,缩到自己服务器的6个pod 上去。这样可以精确控制成本。
php-hpa 定义的最下面,扩大的时候如果 cpu 到了 90%,那么一次性扩大5个pod,缩小的时候一个一个缩,这样避免带来流量的毛刺。
二、自定义指标Prometheus
如上其实已经可以满足大多数要求了,但是想更进一步,比如想从 Prometheus 拿到的指标来进行 hpa 伸缩。
那就比较麻烦了
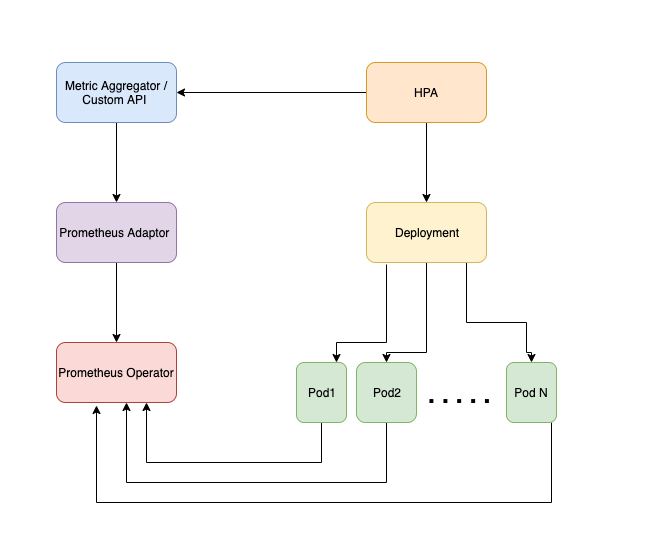
看上图,Prometheus Operator 通过 http 拉取 pod 的 metric 指标,Prometheus Adaptor 再拉取 Prometheus Operator 存储的数据并且暴露给 Custom API 使用。为啥要弄这二个东西呢?因为 Prometheus 采集到的 metrics 数据并不能直接给 k8s 用,因为两者数据格式不兼容,还需要另外一个组件(kube-state-metrics),将prometheus 的 metrics 数据格式转换成 k8s API 接口能识别的格式,转换以后,因为是自定义API,所以还需要用 Kubernetes aggregator 在主 API 服务器中注册,以便其他程序直接通过 /apis/ 来访问。
我们首先来看看如何安装这二个东西:
首先装 Prometheus Operator,这家伙会自动装一捆东西, Pormetheus、Grafana、Alert manager等,所以最好给它单独弄一个命名空间
1#安装
2helm install --name prometheus --namespace monitoring stable/prometheus-operator
3
4#开个端口本地访问 prometheus 的面板,curl http://localhost:9090
5kubectl port-forward --namespace monitoring svc/prometheus-operator-prometheus 9090:9090
6
7
8#看看都有什么pod
9kubectl get pod -n monitoring
10NAME READY STATUS RESTARTS AGE
11pod/alertmanager-prometheus-operator-alertmanager-0 2/2 Running 0 98m
12pod/prometheus-operator-grafana-857dfc5fc8-vdnff 2/2 Running 0 99m
13pod/prometheus-operator-kube-state-metrics-66b4c95cd9-mz8nt 1/1 Running 0 99m
14pod/prometheus-operator-operator-56964458-8sspk 2/2 Running 0 99m
15pod/prometheus-operator-prometheus-node-exporter-dcf5p 1/1 Running 0 99m
16pod/prometheus-operator-prometheus-node-exporter-nv6ph 1/1 Running 0 99m
17pod/prometheus-prometheus-operator-prometheus-0 3/3 Running 1 98m
18
19#看看都有什么svc
20kubectl get svc -n monitoring
21NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
22alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 100m
23prometheus-operated ClusterIP None <none> 9090/TCP 100m
24prometheus-operator-alertmanager NodePort 10.1.238.78 <none> 9093:31765/TCP 102m
25prometheus-operator-grafana NodePort 10.1.125.228 <none> 80:30284/TCP 102m
26prometheus-operator-kube-state-metrics ClusterIP 10.1.187.129 <none> 8080/TCP 102m
27prometheus-operator-operator ClusterIP 10.1.242.61 <none> 8080/TCP,443/TCP 102m
28prometheus-operator-prometheus NodePort 10.1.156.181 <none> 9090:30268/TCP 102m
29prometheus-operator-prometheus-node-exporter ClusterIP 10.1.226.134 <none> 9100/TCP 102m
我们看到有 prometheus-operated 这个ClusterIP svc,注意 k8s 的 coredns 域名解析方式,集群的内部域名是 hbb.local,那么这个 svc 的全 hostname 就是 prometheus-operated.monitoring.svc.hbb.local,集群中可以取舍到 prometheus-operated.monitoring 或者 prometheus-operated.monitoring.svc 来访问。
然后再装 Prometheus Adaptor,我们要根据上面的具体情况来设置 prometheus.url:
1helm install --name prometheus-adapter stable/prometheus-adapter --set prometheus.url="http://prometheus-operated.monitoring.svc",prometheus.port="9090" --set image.tag="v0.4.1" --set rbac.create="true" --namespace custom-metrics
访问 external 和 custom 验证一下:
1kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq
2{
3 "kind": "APIResourceList",
4 "apiVersion": "v1",
5 "groupVersion": "external.metrics.k8s.io/v1beta1",
6 "resources": []
7}
8
9kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq
10{
11 "kind": "APIResourceList",
12 "apiVersion": "v1",
13 "groupVersion": "custom.metrics.k8s.io/v1beta1",
14 "resources": [
15 {
16 "name": "*/agent.googleapis.com|agent|api_request_count",
17 "singularName": "",
18 "namespaced": true,
19 "kind": "MetricValueList",
20 "verbs": [
21 "get"
22 ]
23 },
24[...lots more metrics...]
25 {
26 "name": "*/vpn.googleapis.com|tunnel_established",
27 "singularName": "",
28 "namespaced": true,
29 "kind": "MetricValueList",
30 "verbs": [
31 "get"
32 ]
33 }
34 ]
35}
重头戏在下面,其实 Prometheus Adaptor 从 Prometheus 拿的指标也是有限的,如果有自定义指标,或者想多拿些,就得继续拓展!!!
最快的方式是编辑 namespace 是 custom-metrics 下的 configmap ,名字是 Prometheus-adapter,增加seriesQuery
seriesQuery长这样子,下面是统计了所有 app=shopping-kart 的 pod 5分钟之内的变化速率总和:
1apiVersion: v1
2kind: ConfigMap
3metadata:
4 labels:
5 app: prometheus-adapter
6 chart: prometheus-adapter-v1.2.0
7 heritage: Tiller
8 release: prometheus-adapter
9 name: prometheus-adapter
10data:
11 config.yaml: |
12- seriesQuery: '{app="shopping-kart",kubernetes_namespace!="",kubernetes_pod_name!=""}'
13 seriesFilters: []
14 resources:
15 overrides:
16 kubernetes_namespace:
17 resource: namespace
18 kubernetes_pod_name:
19 resource: pod
20 name:
21 matches: ""
22 as: ""
23 metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[5m])) by (<<.GroupBy>>)
Adapter configmap的配置如下:
-
seriesQuery tells the Prometheus Metric name to the adapter(要去prometheus拿什么指标)
-
resources tells which Kubernetes resources each metric is associated with or which labels does the metric include, e.g., namespace, pod etc.(关联的资源,最常用的就是 pod 和 namespace)
-
metricsQuery is the actual Prometheus query that needs to be performed to calculate the actual values.(叠加 seriesQuery 后发送给prometheus的实际查询,用于得出最终的指标值)
-
name with which the metric should be exposed to the custom metrics API(暴露给API的指标名)
举个例子:如果我们要计算 container_network_receive_packets_total,在Prometheus UI里我们要输入以下行来查询:
sum(rate(container_network_receive_packets_total{namespace=“default”,pod=~“php-deploy.*”}[10m])) by (pod)*
转换成 Adapter 的 metricsQuery 就变成这样了,很难懂:
*metricsQuery: ‘sum(rate(«.series»{«.labelmatchers»}10m])) by («.groupby»)’</.groupby></.labelmatchers></.series>*
再给个例子:
1rate(gorush_total_push_count{instance="push.server.com:80",job="push-server"}[5m])
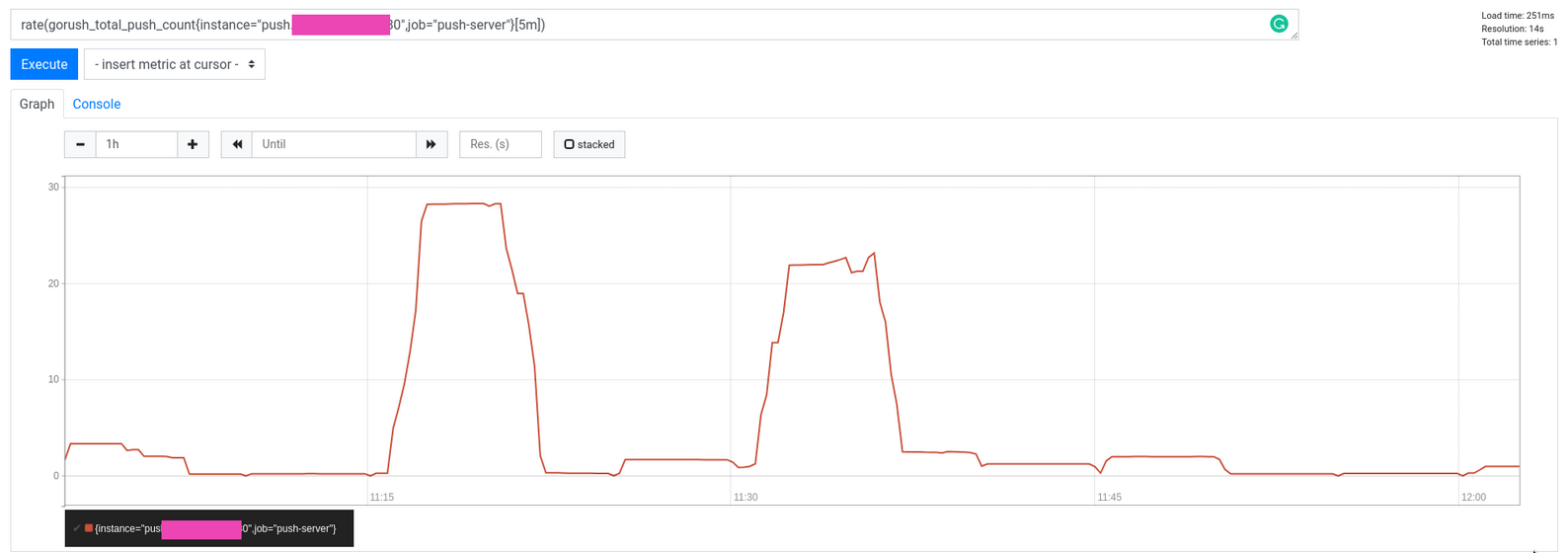
变成 adapter 的 configmap
1apiVersion: v1
2data:
3 config.yaml: |
4 rules:
5 - seriesQuery: '{__name__=~"gorush_total_push_count"}'
6 seriesFilters: []
7 resources:
8 overrides:
9 namespace:
10 resource: namespace
11 pod:
12 resource: pod
13 name:
14 matches: ""
15 as: "gorush_push_per_second"
16 metricsQuery: rate(<<.Series>>{<<.LabelMatchers>>}[5m])
修改了configmap,必须重启prometheus-adapter的pod重新加载配置!!!
在hpa中应用的例子:
1apiVersion: autoscaling/v2beta1
2kind: HorizontalPodAutoscaler
3metadata:
4 name: gorush-hpa
5spec:
6 scaleTargetRef:
7 apiVersion: apps/v1
8 kind: Deployment
9 name: gorush
10 minReplicas: 1
11 maxReplicas: 5
12 metrics:
13 - type: Pods
14 pods:
15 metricName: gorush_push_per_second
16 targetAverageValue: 1m
再来一个,prometheus 函数名是 myapp_client_connected:
1apiVersion: v1
2data:
3 config.yaml: |
4 rules:
5 - seriesQuery: '{__name__= "myapp_client_connected"}'
6 seriesFilters: []
7 resources:
8 overrides:
9 k8s_namespace:
10 resource: namespace
11 k8s_pod_name:
12 resource: pod
13 name:
14 matches: "myapp_client_connected"
15 as: ""
16 metricsQuery: <<.Series>>{<<.LabelMatchers>>,container_name!="POD"}
hpa的使用
1apiVersion: autoscaling/v2beta1
2kind: HorizontalPodAutoscaler
3metadata:
4 name: hpa-sim
5 namespace: default
6spec:
7 scaleTargetRef:
8 apiVersion: apps/v1
9 kind: Deployment
10 name: hpa-sim
11 minReplicas: 1
12 maxReplicas: 10
13 metrics:
14 - type: Pods
15 pods:
16 metricName: myapp_client_connected
17 targetAverageValue: 20
很复杂吧。我们下面给个详细例子
三、自定义指标全套例子
我们先定义一个 deployment,运行一个 nginx-vts 的 pod,这个镜像其实已经自己暴露出了 metric 指标
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: nginx-deploy
5 annotations:
6 prometheus.io/scrape: "true"
7 prometheus.io/port: "80"
8 prometheus.io/path: "/status/format/prometheus"
9spec:
10 selector:
11 matchLabels:
12 app: nginx-deploy
13 template:
14 metadata:
15 labels:
16 app: nginx-deploy
17 spec:
18 containers:
19 - name: nginx-deploy
20 image: cnych/nginx-vts:v1.0
21 resources:
22 limits:
23 cpu: 50m
24 requests:
25 cpu: 50m
26 ports:
27 - containerPort: 80
28 name: http
然后定义个 svc,把80端口暴露出去
1apiVersion: v1
2kind: Service
3metadata:
4 name: nginx-svc
5spec:
6 ports:
7 - port: 80
8 targetPort: 80
9 name: http
10 selector:
11 app: nginx-deploy
12 type: ClusterIP
prometheus 是自动发现的,所以 annotations 就会触发 prometheus 自动开始收集这些 nginx metric指标
集群内起个shell,访问看看
1$ curl nginx-svc.default.svc.hbb.local/status/format/prometheus
2# HELP nginx_vts_info Nginx info
3# TYPE nginx_vts_info gauge
4nginx_vts_info{hostname="nginx-deployment-65d8df7488-c578v",version="1.13.12"} 1
5# HELP nginx_vts_start_time_seconds Nginx start time
6# TYPE nginx_vts_start_time_seconds gauge
7nginx_vts_start_time_seconds 1574283147.043
8# HELP nginx_vts_main_connections Nginx connections
9# TYPE nginx_vts_main_connections gauge
10nginx_vts_main_connections{status="accepted"} 215
11nginx_vts_main_connections{status="active"} 4
12nginx_vts_main_connections{status="handled"} 215
13nginx_vts_main_connections{status="reading"} 0
14nginx_vts_main_connections{status="requests"} 15577
15nginx_vts_main_connections{status="waiting"} 3
16nginx_vts_main_connections{status="writing"} 1
17# HELP nginx_vts_main_shm_usage_bytes Shared memory [ngx_http_vhost_traffic_status] info
18# TYPE nginx_vts_main_shm_usage_bytes gauge
19nginx_vts_main_shm_usage_bytes{shared="max_size"} 1048575
20nginx_vts_main_shm_usage_bytes{shared="used_size"} 3510
21nginx_vts_main_shm_usage_bytes{shared="used_node"} 1
22# HELP nginx_vts_server_bytes_total The request/response bytes
23# TYPE nginx_vts_server_bytes_total counter
24# HELP nginx_vts_server_requests_total The requests counter
25# TYPE nginx_vts_server_requests_total counter
26# HELP nginx_vts_server_request_seconds_total The request processing time in seconds
27# TYPE nginx_vts_server_request_seconds_total counter
28# HELP nginx_vts_server_request_seconds The average of request processing times in seconds
29# TYPE nginx_vts_server_request_seconds gauge
30# HELP nginx_vts_server_request_duration_seconds The histogram of request processing time
31# TYPE nginx_vts_server_request_duration_seconds histogram
32# HELP nginx_vts_server_cache_total The requests cache counter
33# TYPE nginx_vts_server_cache_total counter
34nginx_vts_server_bytes_total{host="_",direction="in"} 3303449
35nginx_vts_server_bytes_total{host="_",direction="out"} 61641572
36nginx_vts_server_requests_total{host="_",code="1xx"} 0
37nginx_vts_server_requests_total{host="_",code="2xx"} 15574
38nginx_vts_server_requests_total{host="_",code="3xx"} 0
39nginx_vts_server_requests_total{host="_",code="4xx"} 2
40nginx_vts_server_requests_total{host="_",code="5xx"} 0
41nginx_vts_server_requests_total{host="_",code="total"} 15576
42nginx_vts_server_request_seconds_total{host="_"} 0.000
43nginx_vts_server_request_seconds{host="_"} 0.000
44nginx_vts_server_cache_total{host="_",status="miss"} 0
45nginx_vts_server_cache_total{host="_",status="bypass"} 0
46nginx_vts_server_cache_total{host="_",status="expired"} 0
47nginx_vts_server_cache_total{host="_",status="stale"} 0
48nginx_vts_server_cache_total{host="_",status="updating"} 0
49nginx_vts_server_cache_total{host="_",status="revalidated"} 0
50nginx_vts_server_cache_total{host="_",status="hit"} 0
51nginx_vts_server_cache_total{host="_",status="scarce"} 0
52nginx_vts_server_bytes_total{host="*",direction="in"} 3303449
53nginx_vts_server_bytes_total{host="*",direction="out"} 61641572
54nginx_vts_server_requests_total{host="*",code="1xx"} 0
55nginx_vts_server_requests_total{host="*",code="2xx"} 15574
56nginx_vts_server_requests_total{host="*",code="3xx"} 0
57nginx_vts_server_requests_total{host="*",code="4xx"} 2
58nginx_vts_server_requests_total{host="*",code="5xx"} 0
59nginx_vts_server_requests_total{host="*",code="total"} 15576
60nginx_vts_server_request_seconds_total{host="*"} 0.000
61nginx_vts_server_request_seconds{host="*"} 0.000
62nginx_vts_server_cache_total{host="*",status="miss"} 0
63nginx_vts_server_cache_total{host="*",status="bypass"} 0
64nginx_vts_server_cache_total{host="*",status="expired"} 0
65nginx_vts_server_cache_total{host="*",status="stale"} 0
66nginx_vts_server_cache_total{host="*",status="updating"} 0
67nginx_vts_server_cache_total{host="*",status="revalidated"} 0
68nginx_vts_server_cache_total{host="*",status="hit"} 0
69nginx_vts_server_cache_total{host="*",status="scarce"} 0
然后用 wrk 随机发狂发请求压一把,我们去 prometheus 的面板看看指标被收集到没有
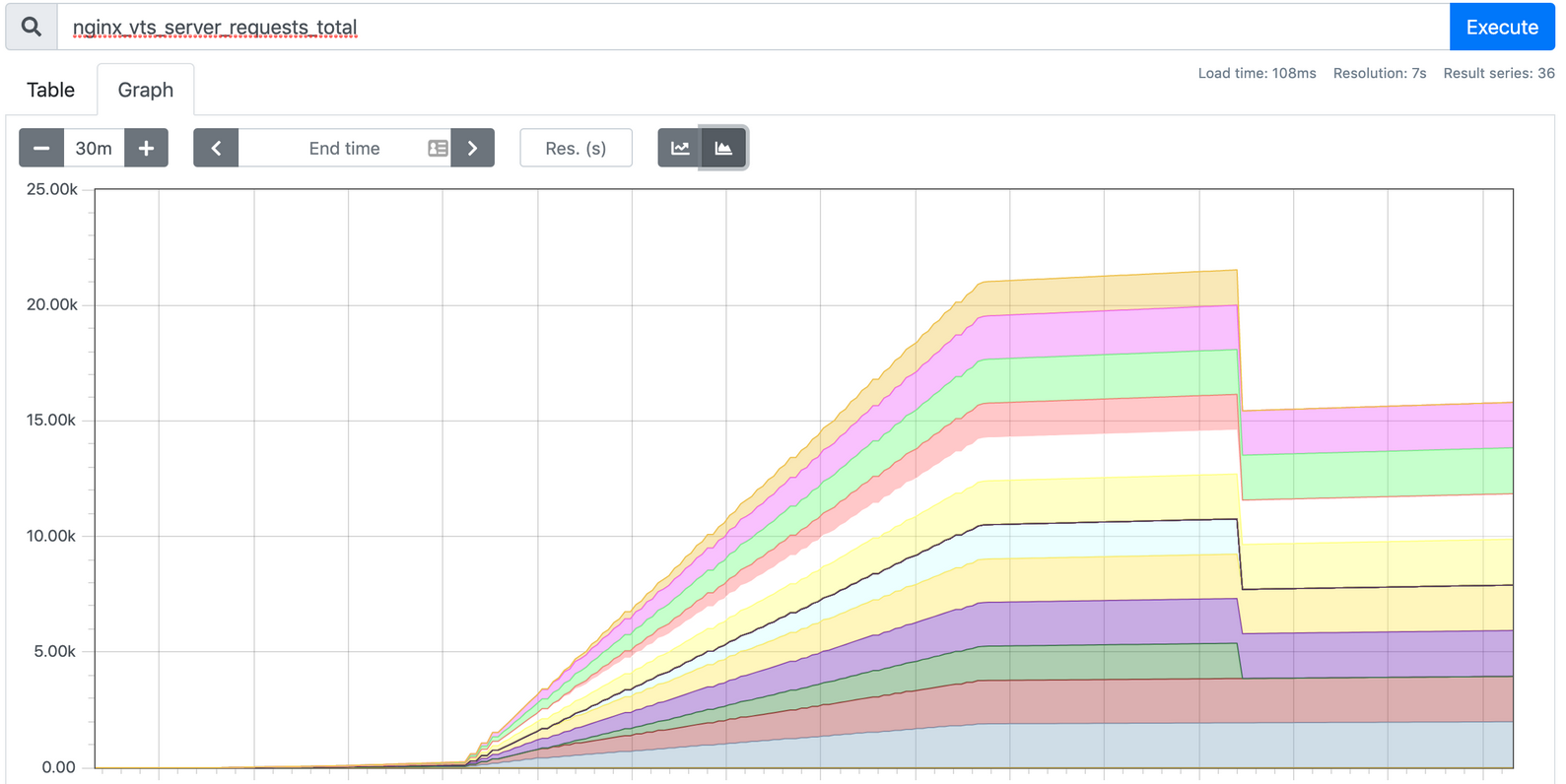
很疯狂啊。我们编辑 Prometheus-Adapter 的 configmap ,加上如下内容
1rules:
2- seriesQuery: 'nginx_vts_server_requests_total'
3 seriesFilters: []
4 resources:
5 overrides:
6 kubernetes_namespace:
7 resource: namespace
8 kubernetes_pod_name:
9 resource: pod
10 name:
11 matches: "^(.*)_total"
12 as: "${1}_per_second"
13 metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>))
然后杀了 Prometheus-Adapter 的 Pod 让它重启重新加载配置,过段时间访问一下,看看值,是527m
1kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_vts_server_requests_per_second" | jq .
2{
3 "kind": "MetricValueList",
4 "apiVersion": "custom.metrics.k8s.io/v1beta1",
5 "metadata": {
6 "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/nginx_vts_server_requests_per_second"
7 },
8 "items": [
9 {
10 "describedObject": {
11 "kind": "Pod",
12 "namespace": "default",
13 "name": "hpa-prom-demo-755bb56f85-lvksr",
14 "apiVersion": "/v1"
15 },
16 "metricName": "nginx_vts_server_requests_per_second",
17 "timestamp": "2020-04-07T09:45:45Z",
18 "value": "527m",
19 "selector": null
20 }
21 ]
22}
ok,没问题,我们定义个hpa,根据这个指标来伸缩
1apiVersion: autoscaling/v2beta1
2kind: HorizontalPodAutoscaler
3metadata:
4 name: nginx-hpa
5spec:
6 scaleTargetRef:
7 apiVersion: apps/v1
8 kind: Deployment
9 name: nginx-deploy
10 minReplicas: 2
11 maxReplicas: 5
12 metrics:
13 - type: Pods
14 pods:
15 metricName: nginx_vts_server_requests_per_second
16 targetAverageValue: 10
这样就好了。
如果 pod 本身不能暴露 metric ,我们可以在 sidecar 里安装 exporter 来收集数据并暴露出去就可以了。

